A Data Pipeline is a set of steps that Extract, Load and Transform data for consumption by the end user. As part of the blog series on Data Pipelines, we spoke about Data Ingestion and the different open-source and commercial players. In this blog we will talk about different data ingestion methods
The need for Data Ingestion types
In an earlier blog, we spoke about the different Data Pipeline types and how the need for data defined the data pipeline. The approaches to data ingestion we are about to explore results from the end user’s need for speed to data consumption. The Data Ingestion methods are:
- Batch
- Real-time
- Lambda Architecture
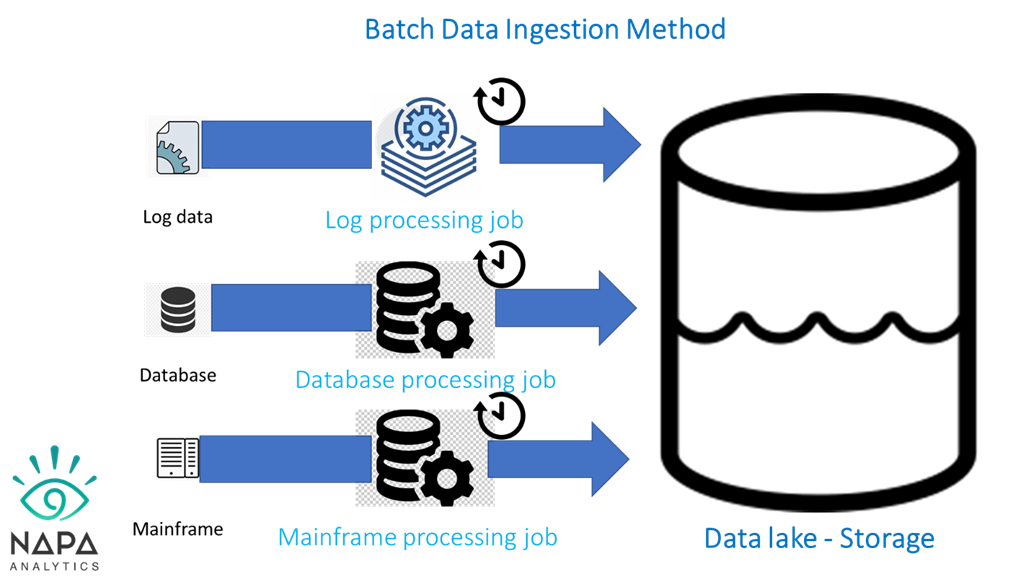
Batch Data Ingestion method
As the name suggests, the data is extracted from the source and moved to the destination at a specified time. The ingestion process could be once data or multiple times a day at a predetermined time. This method is preferred and is the most used ingestion method.
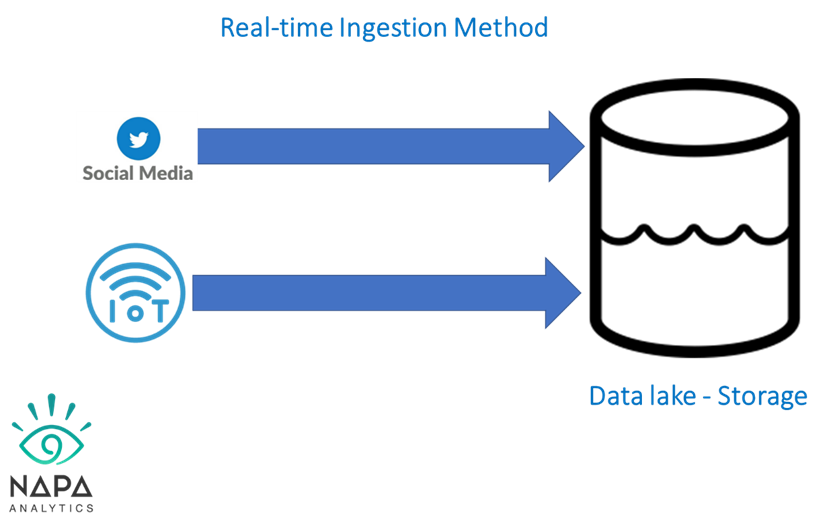
Real-time Data Ingestion Methods
Data ingestion in real-time, also known as streaming ingestion, is ongoing data ingestion from a streaming source. A streaming source can be social media feeds/listens or data from IoT devices. In this method, data retrieval and generation happen simultaneously before storage in the data lake.
Lambda architecture-based Data Ingestion Method
Lambda architecture is a data ingestion setup that consists of both real-time and batch methods. This setup consists of batch, serving, and speed layers. The first two layers index data in batches, while the speed layer instantaneously indexes the data to make it available for consumption. The presence and the activities from each layer ensure that data is available for consumption with low latency.
Summary
Data Ingestion is the first step of the ELT process and das different methods of extracting data from the sources. The data consumption needs of the data users defines the data ingestion methods as either batch, real-time, or lambda architecture. In the next blog as part of the Data Pipeline series we will talk about the Data Storage layer