Data Pipeline is a sequence of steps that deliver consumable data to the end users. Why do we need a sequence of steps? In the present world, data comes from diverse sources in different formats. It is the job of a data engineer to make consumable data available to various consumers. Automated orchestration of these steps is the gist of a data pipeline.
This blog intends to talk about data pipelines. Parts of the data processes are simple, and other parts are complex. Let us start by looking at a typical data process as shown in the figure below:
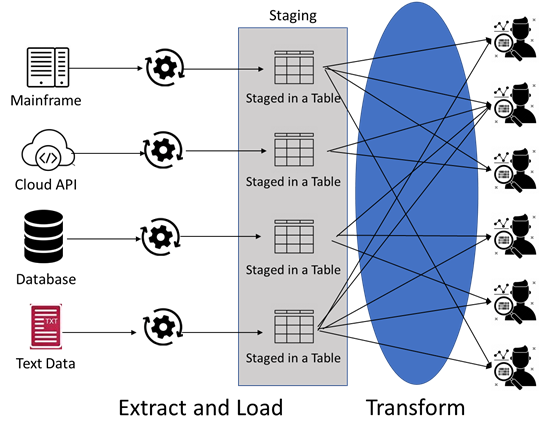
The data from sources is extracted as-is and stored in the staging area. As seen from the above image, the number of data sources are finite. In the example, they are Mainframe, Cloud API, A database, and a text file. The data from the sources is stored in the staging area as one table for each source data table. Changes to the data source data structure and the addition of new data sources is not that frequent. Thus, data the data pipelines for extract and load are standard. We at Napa Analytics have built a python data framework that reduces the time and effort of creating these pipelines.
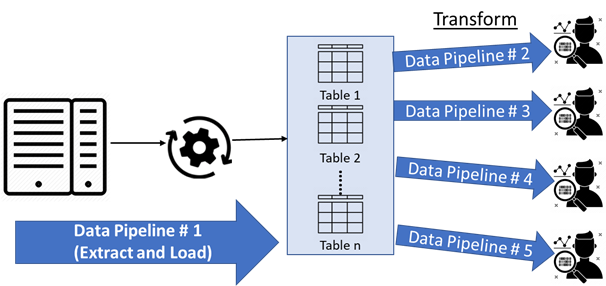
A typical data process can be considered as a combination of more than one data pipelines. The above diagram shows a typical set of data pipelines. For simplicity, we have considered only one data source (a normal situation would have more than one data sources). Dividing the data process into multiple pipelines ensures proper maintenance and ability to perform timely quality checks. Data quality is one of the main concerns with the increasing number of data sources.
Let us discuss the different pipelines:
- Data Pipeline # 1 – This is a straight move from Mainframe data source into staging. Staging will have a one-to-one mapping to the tables in the source database. We could go one step further of de-normalizing the data i.e., flattening the data from the multiple tables into one flat table, which can then be used to extract relevant information.
- Data Pipeline # 2 – 5 – These are the pipelines specific to the user requirement. For example, one of the consumers can be a MicroStrategy user who would require the table structure in a format that would feed the pre-defined reports. Another consumer can be a data analyst who is interested in dimensions and facts for aggregate analysis and reporting. Each of the consumers with their specific needs would require a specific data pipeline.
Data Pipeline(s) that deliver data in consumable format are thus a set of commands that are orchestrated to perform tasks in either sequential or parallel fashion. The initial premise of extract and load can be considered as a generic pipeline, with pipelines for transformation gaining complexity based on the consumer requirements.
The author is a data engineering expert and co-founder of Napa Analytics. Napa Analytics are working on a data framework that enables our clients with tools that reduce the effort (time and knowledge) needed in the creation and maintenance of data pipelines