As part of the Data Pipeline series, in part one and two of the series, we talked about data pipeline and components of data pipeline. The third part deals with types of data pipelines.
The type of data pipeline is related to the need for fresh data. Data pipeline types are traditional (batch) and real-time. Data pipeline types also define the architecture and underlying technology.
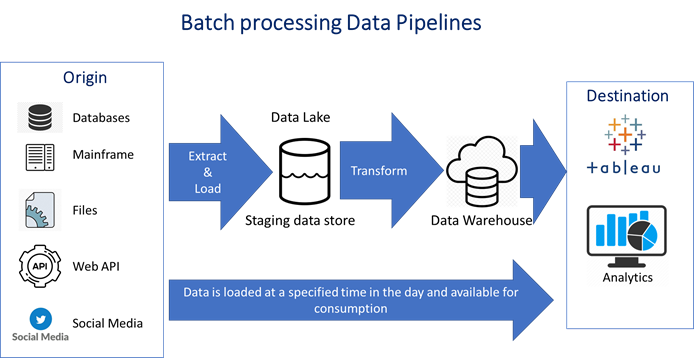
Traditional (Batch) data pipeline
Traditionally, data consumption is for business intelligence and data analytics. The metrics used in business intelligence reports and analytics rely on previous data or data that was generated a few hours earlier. Thus, the data pipeline used for these consumers is a Batch Data Pipeline. As part of the batch process, data is periodically collected, loaded, and transformed at a specified time – could be once or more than once a day. Thus, the architecture and the technologies used for this data pipeline need to:
- Process large amounts of data
- Normally the batch jobs are executed when there is not much activity going on in the source system
- Flexibility on failures. There are options to rerun based on failure type and time allocation
Traditional Data Pipeline use case
A large retailer(with online and brick and mortar presence) has infrastructure on AWS and uses Snowflake
as their centralized data warehouse that receives data from various systems, including their online store transactional data, physical stores legacy POS system, and the web clicks from their website.
The data pipeline that caters to the web analytics team is as follows:
- Data from all the sources is extracted into staging tables in Snowflake
- Data from the staging table is loaded into the Snowflake data warehouse or to specific data marts that provide the end user behavior analytics and the features that describe the behavior
- Data thus aggregated is used in the analytics that is sent to the web marketing team.
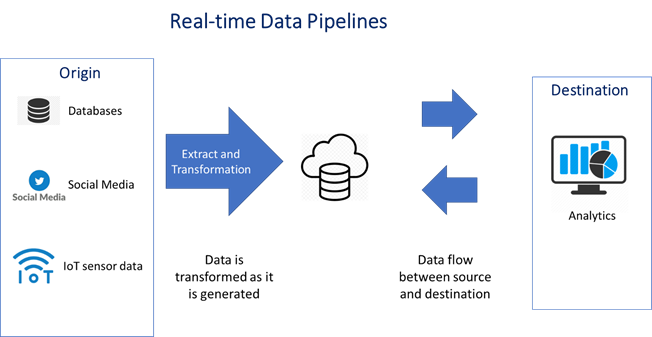
Real time analytics
Data pipelines supporting real-time analytics provide the data and the corresponding analytics as the data is generated, like working with the stream of data called Stream processing. Stream processing is about ingesting data and calculating the metrics and analytics on every piece of data as it is generated. Real-time analytics supporting data pipelines are mainly used in places where there is lot of sensor data used to understand operations and proactively identify potential failures
Real-time analytics use case
A large steel manufacturing company reduced the equipment downtime by actively analyzing sensor data from the machinery. At Napa Analytics, we used the following data pipeline architecture to achieve results for our client:
- Text data ingested from all the machines using Kafka
- Data from Kafka is fed into Apache Spark for calculation and analytics
- Data from Apache Spark is stored in a database
- Messages based on thresholds are sent to distro of engineers.
Near real-time analytics
Real time analytics is not always possible. Sometimes, a compromise needs to be achieved. The compromise is what we can call near real-time analytics. In a sense, near real-time is providing data to the consumers with a time lag of 5 – 10 mins. The data pipeline structure is like the delayed (traditional data pipeline).
Near real-time use case
A large medical insurance provider has the need to look at the medical claims as they enter the system. At Napa Analytics, we used the following data pipeline architecture to achieve results for our client:
- Claims data from Mainframe is read into Hadoop using Apache Flume
- The data is loaded into Apache Kafka
- Processing of the data (metrics and analytics) is done using Apache Spark
- The output is stored in Apache Kudu
- The tables in Apache Kudu feed the Micro Strategy reports
From the three types of data pipelines we have examined, it is evident that data freshness is one of the deciding factors in the data pipeline you choose. If your organization needs support to select the right data pipeline suited to your needs, reach out to Contact – Napa Analytics