In our first article in the series we talked about Data Pipeline. A Data Pipeline is the process of taking data from source and getting it ready for consumption by the end users. This blog intends to explain the different data pipeline components
Data Pipeline consists of eight components as shown in the diagram below:
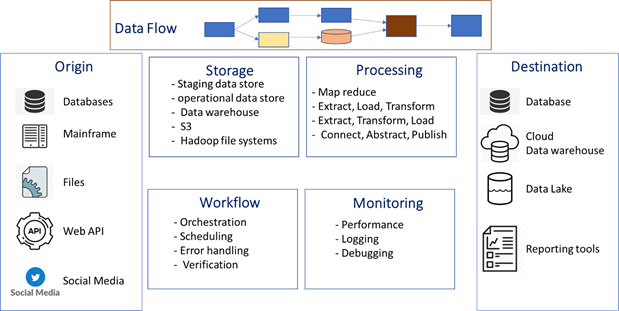
Origin
Origin is where the data is sourced from. Data can be sourced from transaction systems, social media, IoT sensors, application API’s, legacy servers, data warehouse, analytic data stores. The number of data sources and how frequently the data needs to be available for data consumers is increasing every day. Mapping data consumers expectation from the data sources is extremely important to decide the kind of data pipeline treatment given to the data from the source (Origin).
Destination
This where the data is consumed. Thus, this should be the starting point while designing a data pipeline. Data consumer requirements define the data source type, frequency, and transformation. However, the data consumer requirements also bring to light the constraints at the source (Origin). For example, in a large medical insurance company, the medical claims representative needs to see the claims as they are being generated. However, the claims processing systems takes some time (< 1 min) to move the data to the main frame system. It takes some more time for the data to move through the channel to the medical claims representative. The latency thus introduced changes the pipeline delivery SLA from real-time to near real-time. Thus, the final design needs balance data consumer requirements with the capacity and capability of Origin (Data Sources).
Dataflow
Dataflow is a set of steps that need to be orchestrated to deliver the data from Origin to Destination. Dataflow steps can sequential and/or parallel.
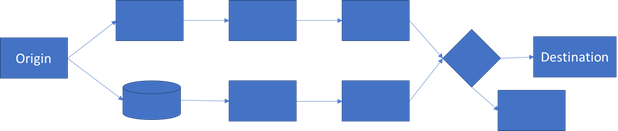
Dataflow steps could take the input from one step to another from Origin to Destination in a sequential manner, which is the most common Dataflow during the initial phases of Data Engineering. As the data consumption requirements mature, there is a need for an intermediate data store while maintaining the original sequential flow, this leads to the parallel data flows.
Data Storage
Data Storage is an intermediary step that enhances the data movement. There are lot of choices for an intermediate data store, and the choice needs to be based on data volume and query complexity. With the advent of new data storage options it is important to choose data storage that can support structure, format, retention duration, and is fault tolerant and has disaster recovery
Processing
This part of the data pipeline is about ingestion, persistence, transformation, and delivery. Each of the processing steps has different methods and things to consider. We will be talking about the methods and consideration in future blogs
Workflow
Workflow defines and manages the data pipeline steps. Workflow ensures that the dependencies for each of the data pipeline steps are satisfied before stating a step. Workflow needs to manage the individual steps and the overall job to achieve the results for the destination
Monitoring
Monitoring is observing the data as it moves through the data pipeline to ensure that the quality of data at the Destination.
The above components are a way to break the Data Pipeline process. Data pipeline is a key component of Data Engineering and we will talk about them in detail in the future blogs. Next Blog we will talk about the types of Data pipelines and the use cases that they support.
At Napa Analytics we take pride in helping clients with their Data Engineering needs and would love to hear from you on your Data Engineering needs/challenges. Please drop us an email at rnemani@napanalaytics.com